The Anatomy of an AI Agent
"AI agents" as they are known today (in 2024) are software applications that utilise the capabilities of large language models (LLMs) to intelligently complete tasks and return results.
In this post, I will explain what goes on behind the scenes in these kinds of systems, what they are made of and how they operate in more complex cases.
Before you read!
This post assumes that you already know about language models and have at least seen one working. It also assumes that you have a fair understanding of some software-related terms like API, machine learning model etc.
Section 1
At the core of an AI agent is a language model (LM), a machine learning model that returns a sequence of output tokens (usually texts) given a sequence of input tokens (also texts) by trying to produce a continuation of the input tokens within the same context.
Input: How are you
Output:? I am fine, thank you. You?
The base versions of most language models are usually modified to operate as instruction-following input-to-output programs, accepting natural language instructions or queries as inputs and returning the results of these queries as outputs, the so-called "instruct models" or "chat models".
Based on this model of operation, we can manipulate the language model to return results in a certain format for certain cases. We acheive this by "prompting" the model; that is, we provide some instructions on how the model should behave in certain situations.
Below is an exchange between a user and a hypothetical language model with a fair degree of capability (i.e a large language model) which has been trained to follow instructions.
System: Return "ERROR!" when the user's query is offensive.
User: Hello
LLM: Hi, how can I help you today?
User: You look like a muffin.
LLM: ERROR!
User: How many days are in a week?
LLM: There are 7 days in a week.
In the interaction above, the agent behaves normally, paying "attention" to the prompt every time a user makes a request and addressing the request based on the instructions in the (systems) prompt, then returning to normal operation afterwards. This is similar to a conditional jump in classical computers, the computer makes a jump to some instructions and returns to the caller to proceed with normal execution. The ability to formulate clever prompts to direct the language model to behave predictably in certain ways is up to the develper and is not covered in this post.
Given now that we can control to a (non-negligible) degree how the model returns its results, we can then do useful work with it. This is the most fundamental operation of a so called "AI Agent": Recieve input and process the input based on the system prompt. Lets try to visualise this:

You can make do with even this simple architecture and create an agent the just answers question (which is a kind of work in itself). To build more sophisticated types on agents, we need to extend this achitecture.
1. Input: The medium through which input is passed to the language model.2. Context Window: A finite sized container of tokens that a language model can consume data from at inference time. It operates as the immediate memeory of the model. The context is made up of the system prompt, the user's input and the models output.
3. The language model.
4. Output: The medium through which the output of the model is passed to other external components.

Input
In principle, any medium that returns text that can be useful to the language model for inferencing can operate as the input medium or channel. However, in more sophisticated systems, the input channel isn't as simple as a regular text console/terminal, in fact, the input medium can it self be a chain of various conversion layers whose final output is then the text that can be consumed by the language model.
Let's take a look at the architecture of the input chain for a hypothetical agent that returns a list of the key takeaways in a lecture stored as an audio file.
 The final input text goes into the language model after some pre-processing (cleaning the result of the
transcription service before passing it to the language model) is done. The pre-processing routine may include reformatting the transcription into
a format that matches the expectation of the LLM's system prompt or even the core language model itself in cases where it has been
finetuned on datasets of a specific format.
The final input text goes into the language model after some pre-processing (cleaning the result of the
transcription service before passing it to the language model) is done. The pre-processing routine may include reformatting the transcription into
a format that matches the expectation of the LLM's system prompt or even the core language model itself in cases where it has been
finetuned on datasets of a specific format.
Context Window
The context contains the data that is available to the language model at inference time. You can imagine the context of a LM as its immediate or primary memory similar to the RAM of a classical computer, which also houses data that must be available to a computer program at run time. Like I mentioned earlier, the system prompt provided to the LM and the LM's completions or outputs all make up the context. Since the context is finite in size, developers must make the best use of it by ensuring that that data available to the LM at inference time is the data that is most useful to the task at hand so as to avoid running out of context tokens (remember that every new token generated also makes up the context). There are clever techniques that can be employed to make the best use of the context window, similar to memory management techniques in operating systems; from loading relevant data from external sources to giving the illusion of an infinite context window. Some of these will be treated in future posts, God willing.
Output
As mentioned, the output of a language model is also text and there is a lot we can do with that. The first consumer of the LM's output is the LM itself at inference time since the generated output is appended to any context token available. The generation is also returned on a per-token basis as the output-per-inference from the language model. The developer may then choose to accumulate these results or stream them as they are generated to whereever they may be further used.

In principle, any system that takes text as an input can consume the final result of the LM, and this includes the original LM itself. This feedback mechanism makes for some reflexive behaviour where the agent can determine its next behaviour based on its previous result. This approach is most useful when the AI agent needs to consume its previous result for further or even deeper processing. Imagine an agent that lists a series of tasks that is to be completed and then recursively breaks down the individual tasks into subtasks. I may dedicate a whole series to this technique in the future.

Like the input layer, the output layer could also be a chain of sub-modules that work in series or in parrallel to convert the LM's text output to the preferred output format of the whole system.
This coupling of modules and sub-modules is what makes up an AI agent. As the behaviour of the agent can be declared at a low high level by prompting the language model, so can it also be declared at a high level in the software framework e.g determining when to spawn a new thread or storing the state of the agent in an application-wide cache. All these will come as separate posts in the future.
The "Agent Computing" Model
At this point, we can see that there are many similarities between the high-level operations of LLM-base AI agent and that of the von-nouman model of classical computing. The Agent Computing Model (not an official name. I made it up!) is a hypothetical model that tries to draw some similarities between LLM-based systems and classical computers, thereby introducing some methods and techniques from the classical computing model to address certain problems in LLM-base system. By looking at each components of an LLM-Powered AI agent, it is possible to apply some of the methods in classical computing to agent.
Below is an image created by the legendary Andrej Karpathy of OpenAI that illustrates how an LLM based AI agent can be modeled like a classical computer.
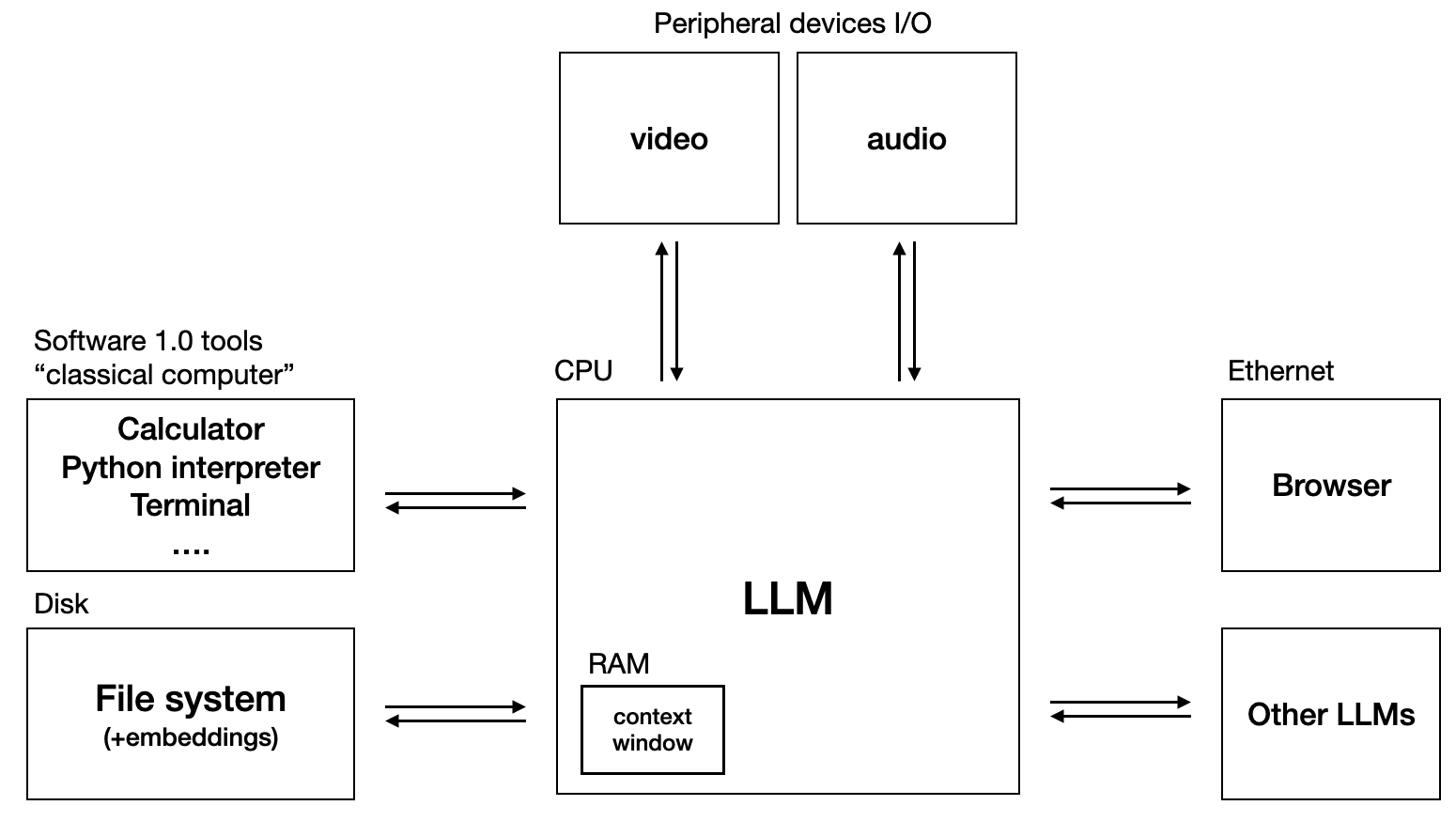 Source: Andrej Karpathy's
Twitter
Source: Andrej Karpathy's
Twitter And the following is another image from the MemGPT paper that extends this model with components from classical computer like virtualised context (similar to virtual memeory) to theoretically give the language model virtual context, similar to how virtual memeories extend the physically addressable memory in classical computers.
 Source: MemGPT Paper
Source: MemGPT Paper
The synergy of Agents
An even more sophisticated architecture usually involves agents working in parrallel and in series to solve a single problem.
There are many things to consider when building a system of non-deterministic modules/components. Although we can draw similarities between these new kinds of systems and the original models that govern classical computers, however, the differences are way more attention-worthy than the similarity. This introduces a new class of problems that forces develpers to think more deeply about how they approach certain problems. Below are some questions that arise?
- How do you ensure determinism in a non-deterministic system?
- How do you validate the output of these systems?
- Can we ensure that results are based on actual data or a victim of the infamous hallucination problem?
- Can these systems be trusted with complex reasoning tasks?
- If all this is still happening on the application level on an actual computer, then how do we ensure performance given that an AI agent is still a piece of software?
In my future posts, I will try to adress how developers approach some of these problems and also introduce some exciting things you can achieve when you finally get a hang of working with these models.
Thank you for reading, be sure to let me know if you spot any errors.